8加载数据集
前情提要:
因为有鞍点的存在,可能会导致深度学习在循环中共,无法继续往梯度下降的方向进行。
所以我们选择了随机梯度下降算法,而不是求平均loss的梯度下降算法。
我的理解就是使用不确定性的好来对抗确定性的差

把所有样本进行了前馈,和反向传播
就是一轮epoch
00:04:45.488

每次训练中所用的样本数量

这里没有上上上图中的for i in range
所以这里就是所有的数据都进行随机梯度下降计算
00:05:09.337

iteration(这块理解比较抽象)
batch分了多少个
比如有1000个数据
100是batch-size
经过了10次的迭代,以100 batch-size的方式实现了1000个数据训练
shuffle 打乱顺序
00:07:09.352

00:07:53.784

00:08:41.339
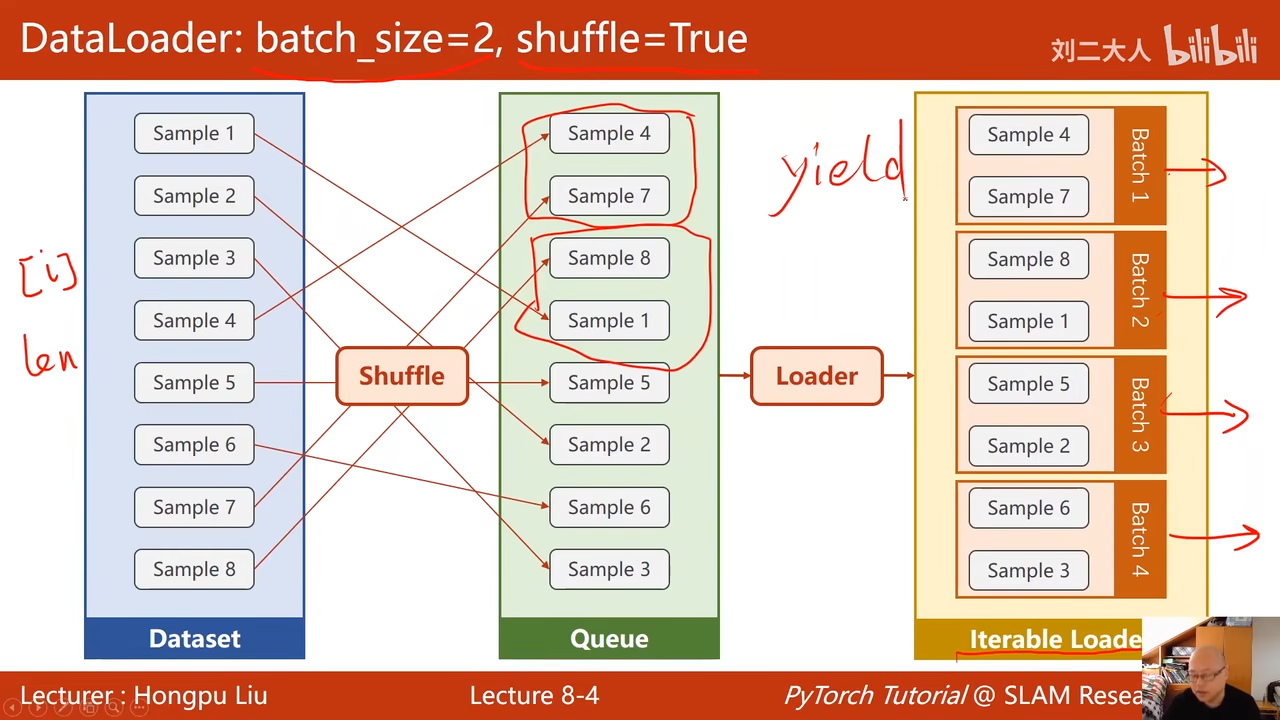


用来加载数据,可以实例化一个dataloader
dataset是一个抽象类,不能实例化

getitem是实例化之后,可以进行下标搜索
00:11:46.675

len返回数据条数
1.
self.len = xy.shape[0] # shape(多少行,多少列)

构造数据集的选择:
- 把所有数据data中,通过init加载进来,通过getiemc传出去
适用于图像数据集不大 - init中只是进行初始化,定义一个列表,把数据的文件名放到列表中。可能还会涉及到读取标签,如果标签不大也可以直接用init读
图像语音-》无结构的数据
dataloader
00:17:55.684

四个参数
传入数据集
batchsize容量是多少
是否打乱(最好还是打乱
是否使用并行进程
windows中编程与linux在使用多线程的区别
如果选择num_worker,其实也就是多线程,windows中则需要加入 if_name_=…



这个是方法1,把所有的数据都保存到内存当中了
00:24:18.609

00:27:12.228

使用enumerate为了获取迭代次数
trainloader中的数据放到data中
然后经过inputs和label分割成xy
剩的东西都没啥区别




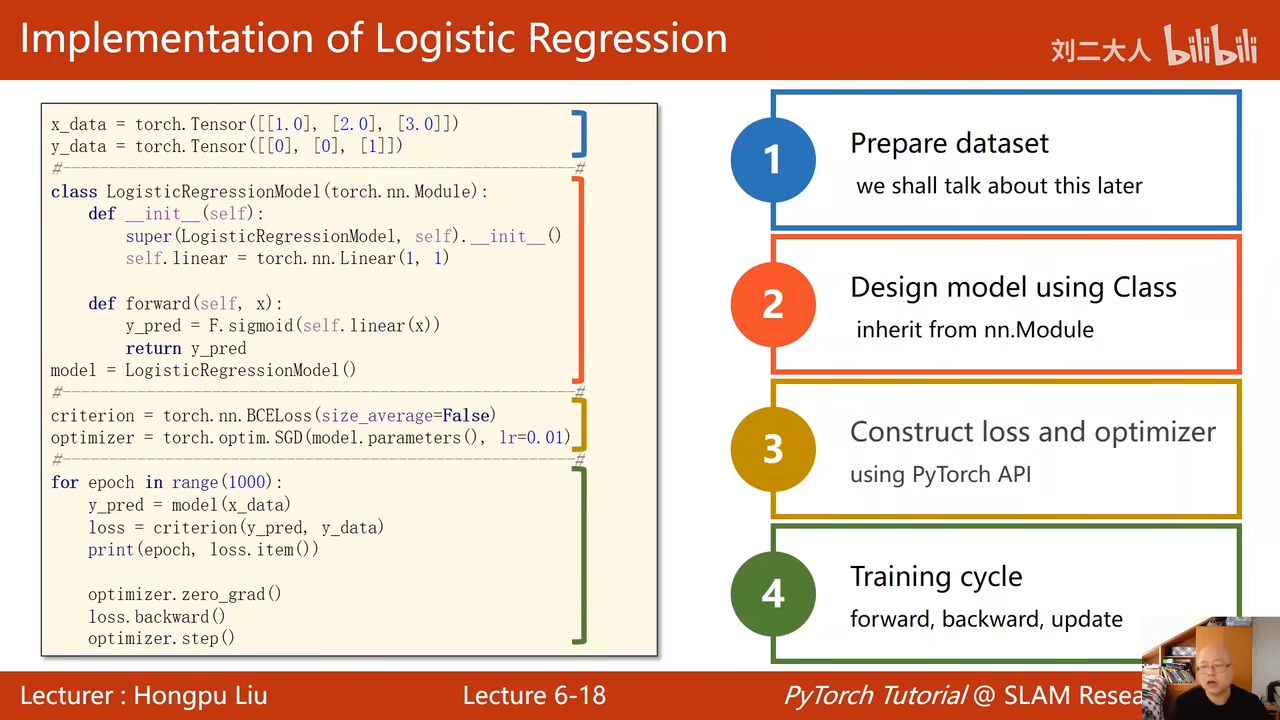
- 准备数据集
- 设计模型
- 构造损失和优化器
- 训练循环
这一节在训练循环中加入了mini-batch
trainloader就是构建了batch

一些提供的数据集

不做shuffle为了便于观察

作业
kaggle
使用dataloader构造一个分类器